Map/Reduce in Java-8
The new Streams API in Java-8 has enriched the collections to a great level. If you are looking to get into BigData domain and work on Map/Reduce programs, streams has made the code way too simpler and easier to understand.
Map is pretty simple where you can transform the elements of a collection into another object and use them in your code without writing much code-
Ex:
package com.example.mapreduce;import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;public class MapReduceProgram
{
public static void main(String[] args)
{
String [] values = new String[] {"abc","def","ihj","pqr"};
List<String> results = Arrays.asList(values).stream().map(value -> value.toUpperCase()).collect(Collectors.toList()); System.out.println(results);
}}
Reduce
Reduce provides a single result out from the analysis of elements of a collection.
There are three main arguments for the reduce function-
Identity
This is the initial value for the reduce function and if the stream is empty then this is the default value of the reduce operation.
Accumulator
This function aggregates the data based on the business logic written in the function. It has two inputs, one is the partial result of the reduce operation and another is the next element in the array.
Combiner
This comes into play when you have parallel streams to be processed by the reduce function or the arguments for reduce function are not same as that of the output of reduce function.
Let’s understand reduce() with a couple of examples-
package com.example.mapreduce;import java.util.Arrays;
import java.util.List;public class ReduceProgram
{
public static void main(String[] args)
{
Integer[] values = new Integer[] {3 , 4, 7, 8, 11, 23};
List<Integer> asList = Arrays.asList(values);
int result = asList.stream().reduce(0, (partialResult , value) -> partialResult + value);
System.out.println("Total is :: "+ result);
}
}
The output of the above program is 56, which is the sum of all elements of the array
Here, 0 is the seed value and partialResult is the intermediate result and value is the element being iterated over-
Let’s see how it works, by putting a print statement-
package com.example.mapreduce;import java.util.Arrays;
import java.util.List;public class ReduceProgram
{
public static void main(String[] args)
{
Integer[] values = new Integer[] {3 , 4, 7, 8, 11, 23};
List<Integer> asList = Arrays.asList(values);
int result = asList.stream().reduce(0,
(partialResult , value) ->
{
System.out.println("Partial result :: " + partialResult);
System.out.println("Value :: " + value); return partialResult + value;
}); System.out.println("Total is :: "+ result); }
}
The below is the output of the program-
Partial result :: 0
Value :: 3
Partial result :: 3
Value :: 4
Partial result :: 7
Value :: 7
Partial result :: 14
Value :: 8
Partial result :: 22
Value :: 11
Partial result :: 33
Value :: 23Total is :: 56
As you see partialResult variable keeps track of the current sum, whereas value is the next element in collection-
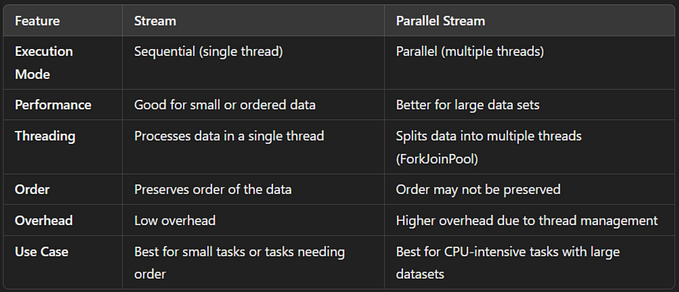
Reduce being used in parallel streams
In the section above I mentioned about Combiner, which is used when input and output of reduce function aren’ t of the same data-type or we are working on parallel streams.
Let’s create a plain and simple Employee class-
public class Employee
{
private String name;
private Integer salary;
public Employee(String name, Integer salary)
{
this.name = name;
this.salary = salary;
} public String getName()
{
return name;
} public void setName(String name)
{
this.name = name;
} public Integer getSalary()
{
return salary;
} public void setSalary(Integer salary)
{
this.salary = salary;
}}
Now, let’s run the same code in parallel streams-
import java.util.ArrayList;
import java.util.List;public class MapReduceParallelProgram
{ public static void main(String[] args)
{ List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("Emp-1", 23000));
employeeList.add(new Employee("Emp-2", 24000));
employeeList.add(new Employee("Emp-3", 28000));
employeeList.add(new Employee("Emp-4", 25000));
employeeList.add(new Employee("Emp-5", 27000));
employeeList.add(new Employee("Emp-6", 27000));
employeeList.add(new Employee("Emp-7", 23000));
employeeList.add(new Employee("Emp-8", 27700));
employeeList.add(new Employee("Emp-9", 23100)); int sumValue = employeeList.parallelStream().reduce(0, (value, employee) -> {
System.out.println("Operating on: "+ employee.getName());
return value + employee.getSalary();
}, Integer :: sum); System.out.println("Final value is: "+ sumValue); }
}
The output is-
Operating on: Emp-5
Operating on: Emp-1
Operating on: Emp-7
Operating on: Emp-4
Operating on: Emp-2
Operating on: Emp-8
Operating on: Emp-3
Operating on: Emp-6
Operating on: Emp-9Final value is: 227800
As you see, it’s not processing in a sequential order but in parallel. The output of program will vary as the streams are running in parallel.